Building Prodigy: Our new tool for efficient machine teaching
I’m excited and proud to finally share what we’ve been working on since launching Explosion AI, alongside our NLP library spaCy and our consulting projects. Prodigy is a project very dear to my heart and seeing it come to life has been one of the most exciting experiences as a software developer so far.
A lot of the consulting projects we’ve worked on in the past year ended up circling back to the problem of labelling data to train custom models. Data annotation can be very tedious and time consuming. You need to select the examples, write manuals and hire annotators for the boring work. As a result, many companies dread this process. I’ve always had a hard time accepting that this was simply how things are.
When we first started working on the idea of a better, more efficient annotation tool, we were met with some skepticism. “Annotation is boring, that’s just how it is. Why do you care about making it enjoyable?” Conversations like these were what inspired last year’s post about huge potential of better tooling and UX for AI development.
In many cases, the creation of annotated data can seem like the ultimate unskilled labour. This suggests a tempting theory: annotation time should be dirt cheap, right? If so, then investment in annotation tools should be a waste. Just buy more labour. I think if you try this, you’ll see that people don’t behave so simply. The workers you’re hoping to hire so cheaply are homo sapiens, not homo economicus.
How front-end development can improve Artificial Intelligence
Prodigy takes this idea one step further, by letting developers and data scientists train models interactively, test out ideas and collect annotations themselves. Instead of wasting a human’s time with boring interfaces and repetitive questions, it uses what the model already knows to suggest what to ask next, and reduces the annotation to a simple, binary decision: yes or no. It’s a downloadable tool with a powerful command-line interface for training and evaluating models, and a flexible web application for collecting annotations straight from the browser.
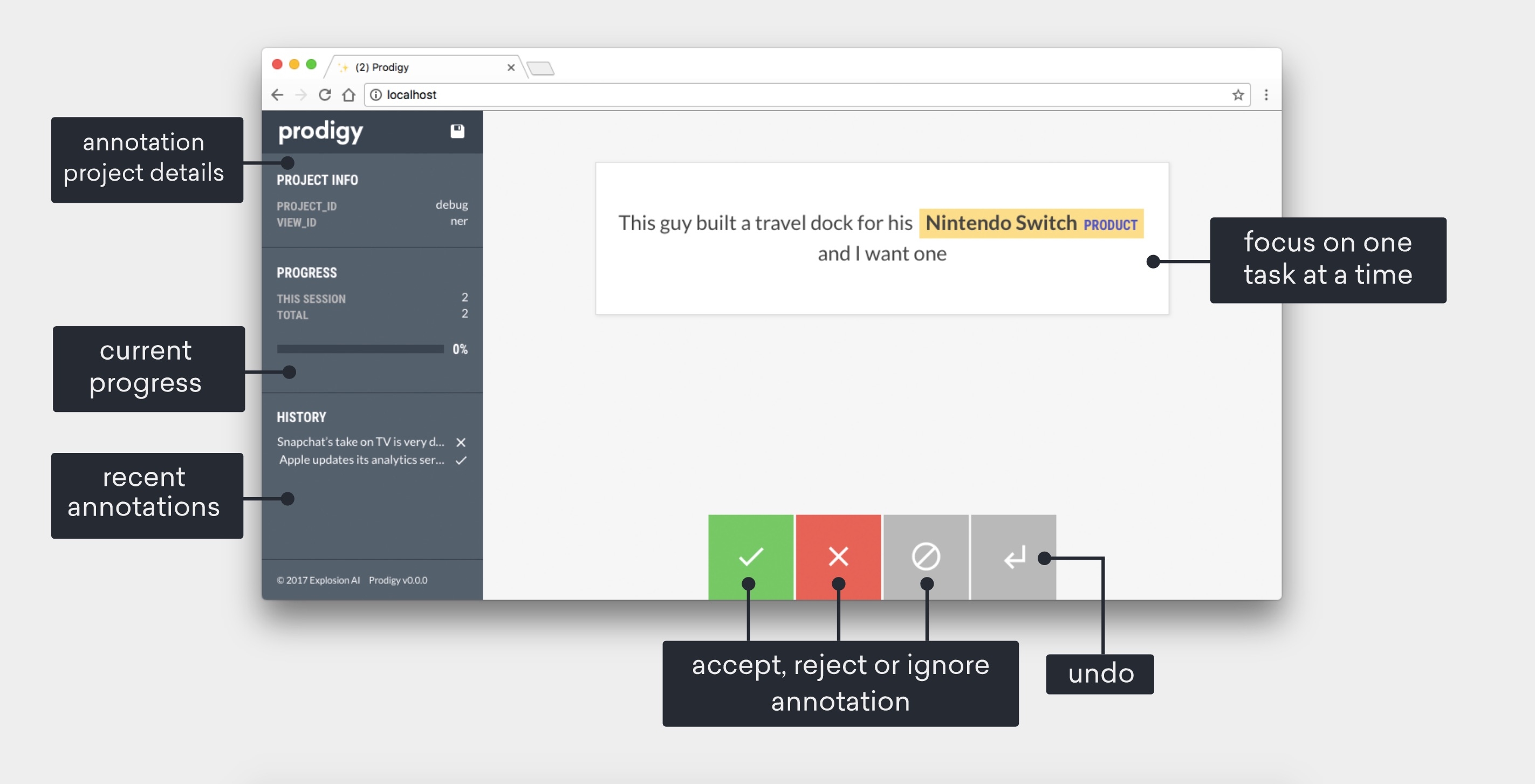
While the web application was what originally inspired Prodigy, it quickly grew into a more complex “machine teaching” tool. At the core of it are recipes, Python functions that orchestrate data streams, update the model and if necessary, start the web server to collect annotations. In other cases, recipes can simply run a training loop, or evaluate an already trained model using an evaluation set created with Prodigy. There are built-in recipes for training models with live annotations, recipes to batch train from already annotated datasets, recipes to test different training configurations and recipes to evaluate trained models.
A big challenge when designing user APIs is keeping the right balance between out-of-the-box functionality, simplicity, and extensibility. How much can you assume about a user’s workflow? Where do you offer built-in hooks, and when, how and where do you ask the user to customise? Recipes seemed to be the best way to address this problem: the built-in ones cover most basic use cases, while custom recipes allow executing any Python code and returning a dictionary of components to use.
prodigy my_recipe my_dataset -F my_recipe.py@prodigy.recipe('my_recipe')
def my_recipe(dataset):
model = load_my_model()
stream = load_my_stream()
return {'dataset': dataset, 'stream': stream, 'update': model.update}Why Prodigy is cloud-free
Prodigy will be a downloadable tool with a lifetime license, that you can install and run yourself – not a subscription service. This has become an unusual choice for a software startup. SaaS is a very popular business model and supposedly “the way to go”, because it promises repeat revenue and is very attractive to investors. However, not all tools are a good fit for a service model. Making Prodigy work “in the cloud” would mean taking away most of its benefits: running it on your local machine, streaming in your own data without having to upload it to a third-party server and easily configuring it with simple Python scripts.
For now, Prodigy’s main focus is making data science workflows easier, and allowing rapid iteration on both the code and the data. Because annotations can be collected quicker and models require less annotations to produce first results, it’s easier to conduct supervised learning experiments and find out whether an idea is working or not. This works best with extensible tools, not services.
Without a service layer, there was one problem, though: securely sharing annotation projects online, for example, to use Prodigy on your phone, or send the project over to a colleague or an external annotator. Running it on your server with a password-protected front-end is possible, but inconvenient. Ultimately, we decided on an end-to-end encrypted REST service that communicates with the user’s local machine. Annotation tasks are encrypted locally and decrypted only on the client in the web app by the annotator. The only data that will leave the user’s servers and hit ours is encrypted annotation tasks.
Next steps
Prodigy is currently in beta – you can still apply via the the website. Many of the beta signups we’ve received so far included interesting usage ideas from all kinds of different fields. We’re looking forward to shipping Prodigy to developers so it can be put to work.
To read more about Prodigy and see it in action, you can check out our blog post, see the more detailed docs and play with the live demo.